Publications
A collection of my research work.
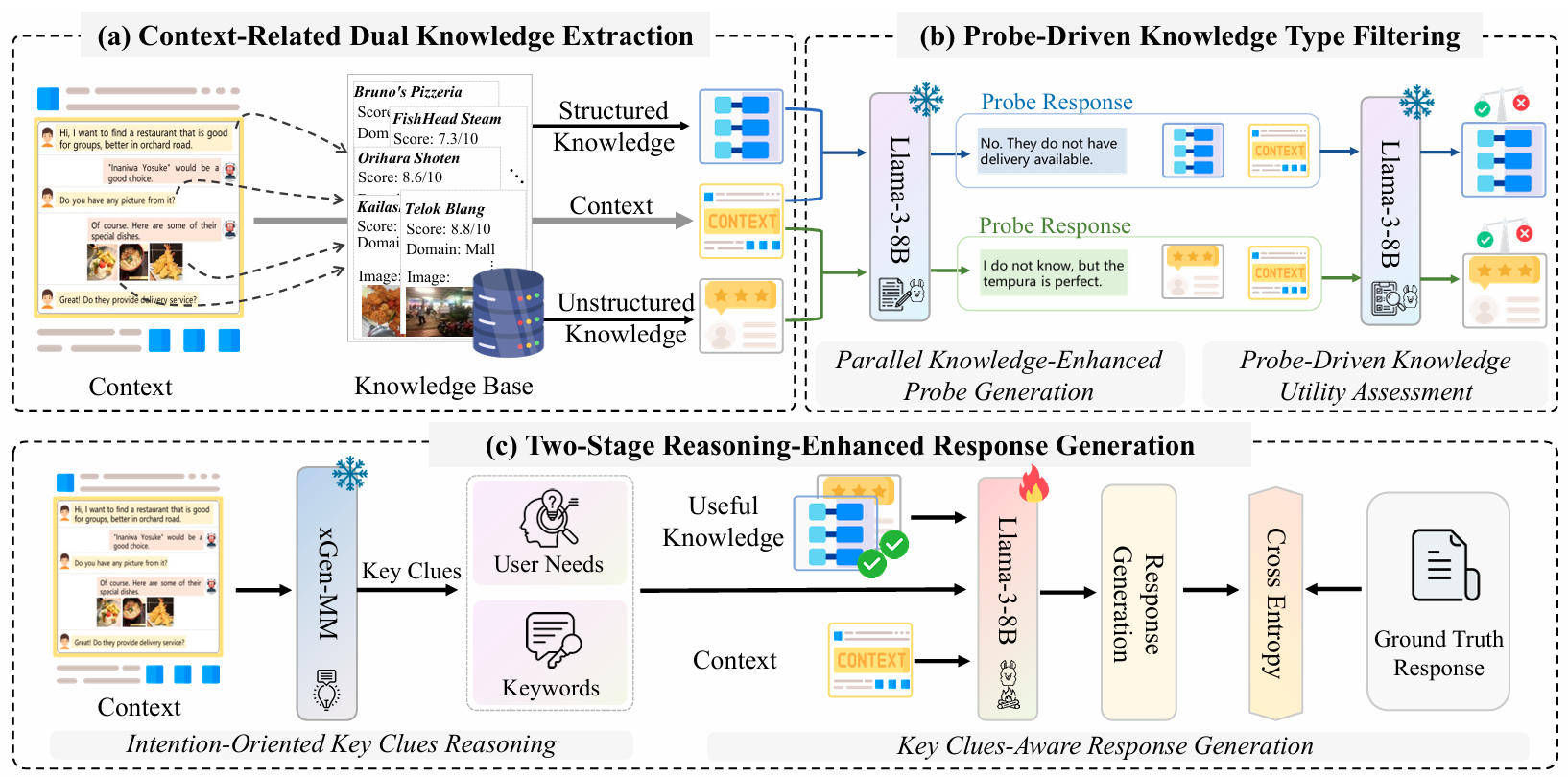
Dual Knowledge-Enhanced Two-Stage Reasoner for Multimodal Dialog Systems
Xiaolin Chen, Xuemeng Song, Haokun Wen, Weili Guan, Xiangyu Zhao, Liqiang Nie
arXiv preprint arXiv:2509.07817 2025
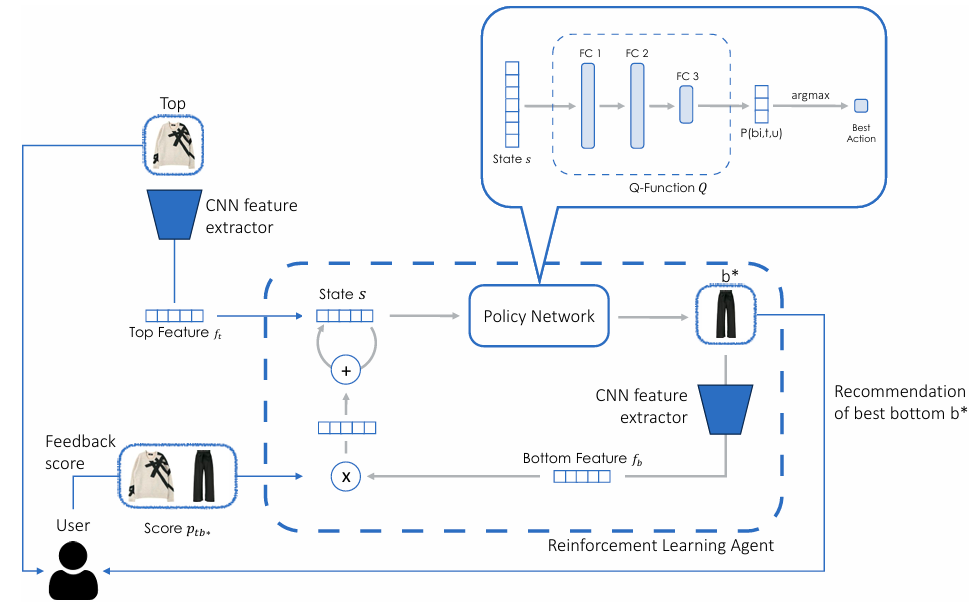
Interactive Garment Recommendation with User in the Loop
Federico Becattini, Xiaolin Chen, Andrea Puccia, Haokun Wen, Xuemeng Song, Liqiang Nie, Alberto Del Bimbo
ACM Transactions on Multimedia Computing, Communications, and Applications 2025
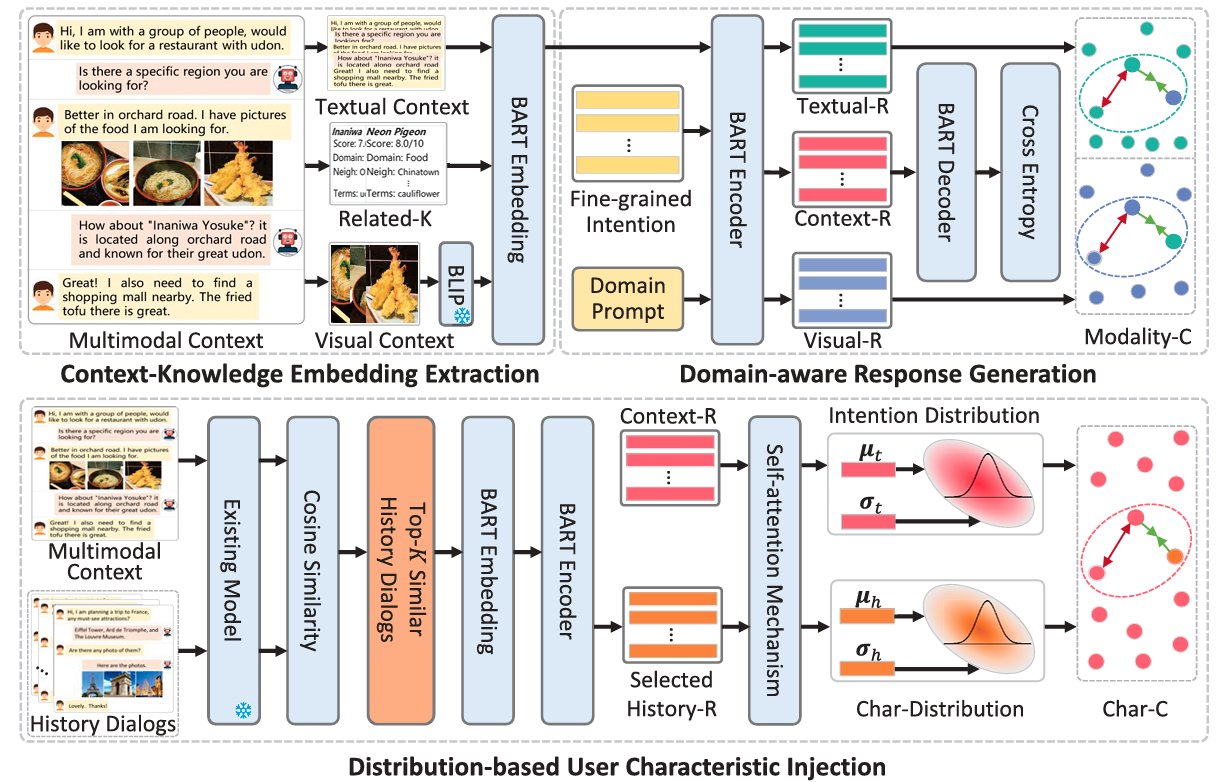
Domain-aware Multimodal Dialog Systems with Distribution-based User Characteristic Modeling
Xiaolin Chen, Xuemeng Song, Jianhui Zuo, Yinwei Wei, Liqiang Nie, Tat-Seng Chua
ACM Transactions on Multimedia Computing, Communications, and Applications 2024
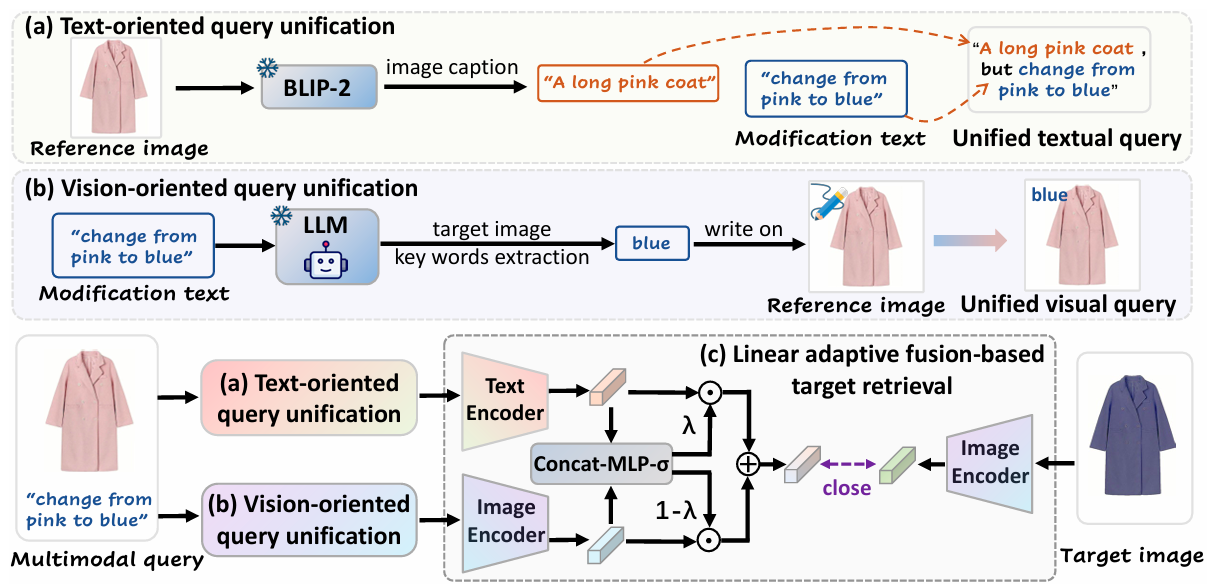
Simple but Effective Raw-Data Level Multimodal Fusion for Composed Image Retrieval
Haokun Wen, Xuemeng Song, Xiaolin Chen, Yinwei Wei, Liqiang Nie, Tat-Seng Chua
Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval 2024
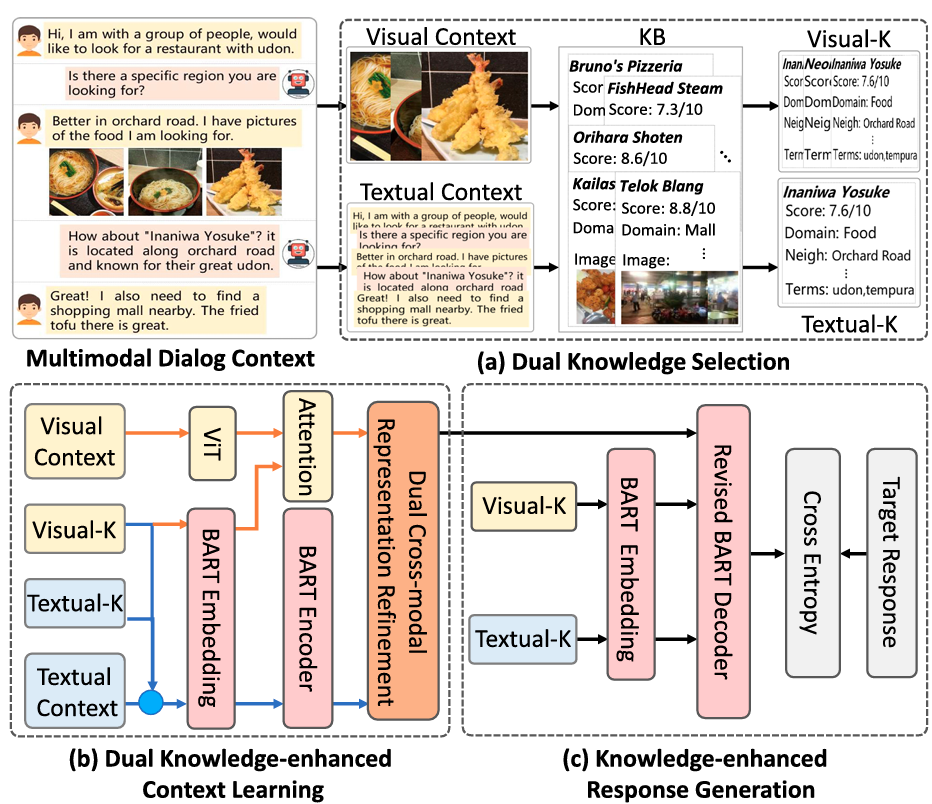
Multimodal Dialog Systems with Dual Knowledge-enhanced Generative Pretrained Language Model
Xiaolin Chen, Xuemeng Song, Liqiang Jing, Shuo Li, Linmei Hu, Liqiang Nie
ACM Transactions on Information Systems 2023
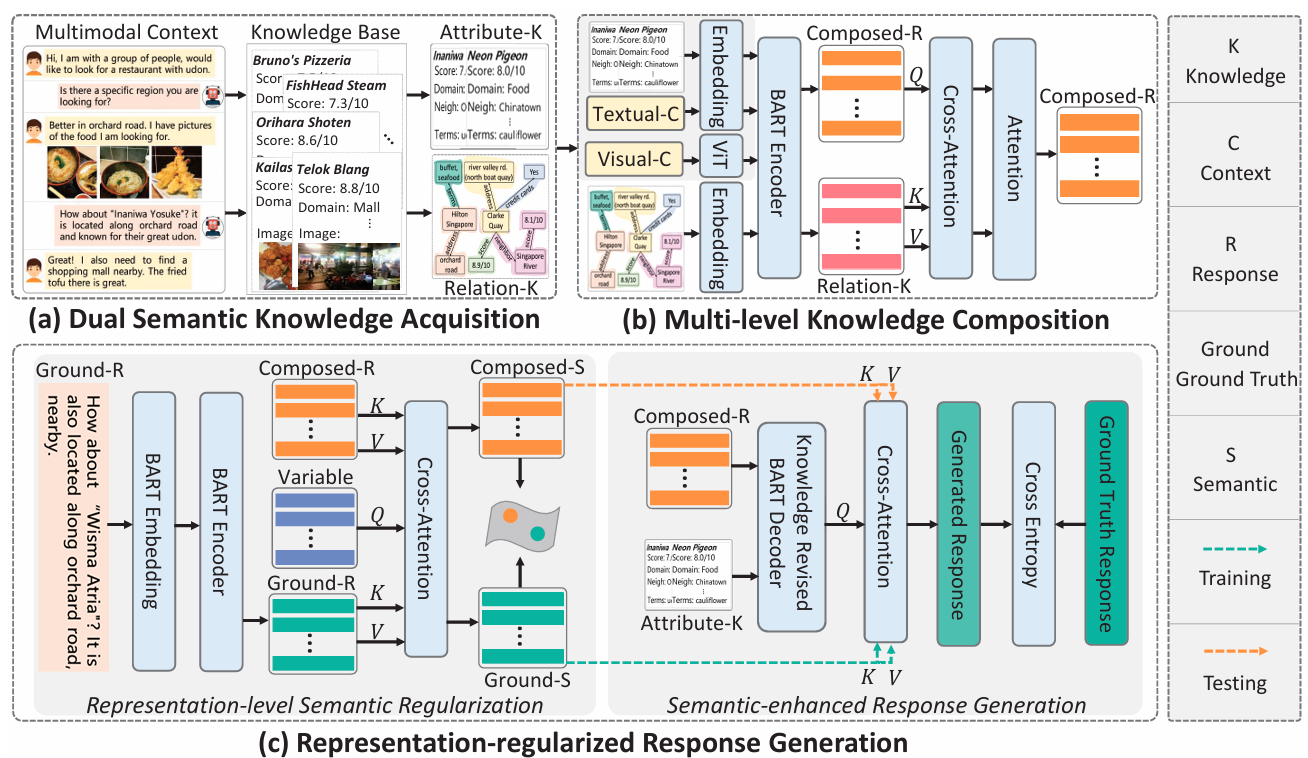
Dual Semantic Knowledge Composed Multimodal Dialog Systems
Xiaolin Chen, Xuemeng Song, Yinwei Wei, Liqiang Nie, Tat-Seng Chua
Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval 2023
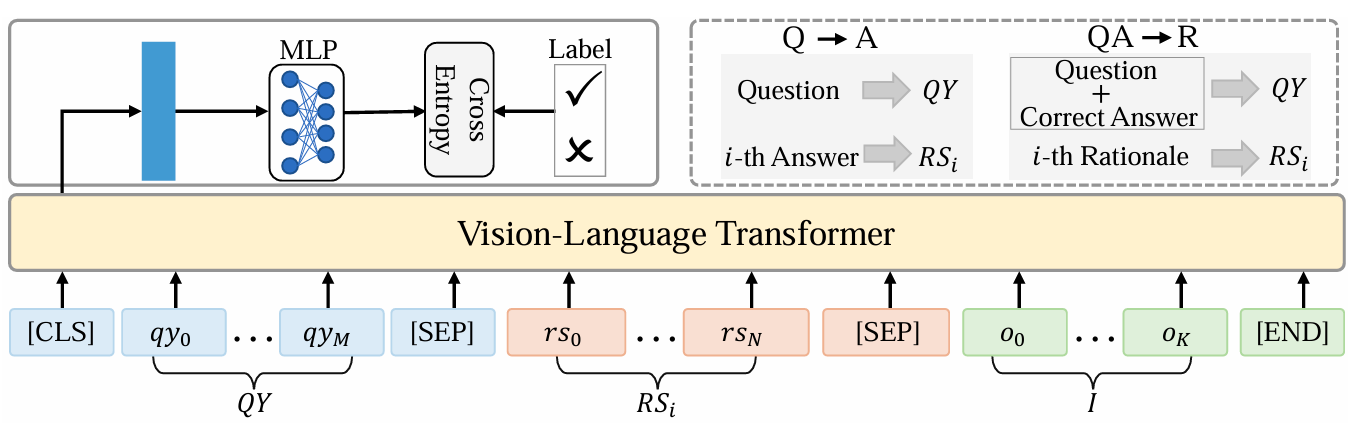
Do Vision-Language Transformers Exhibit Visual Commonsense? An Empirical Study of VCR
Zhenyang Li, Yangyang Guo, Ke-Jyun Wang, Xiaolin Chen, Liqiang Nie, Mohan Kankanhalli
Proceedings of the ACM International Conference on Multimedia 2023
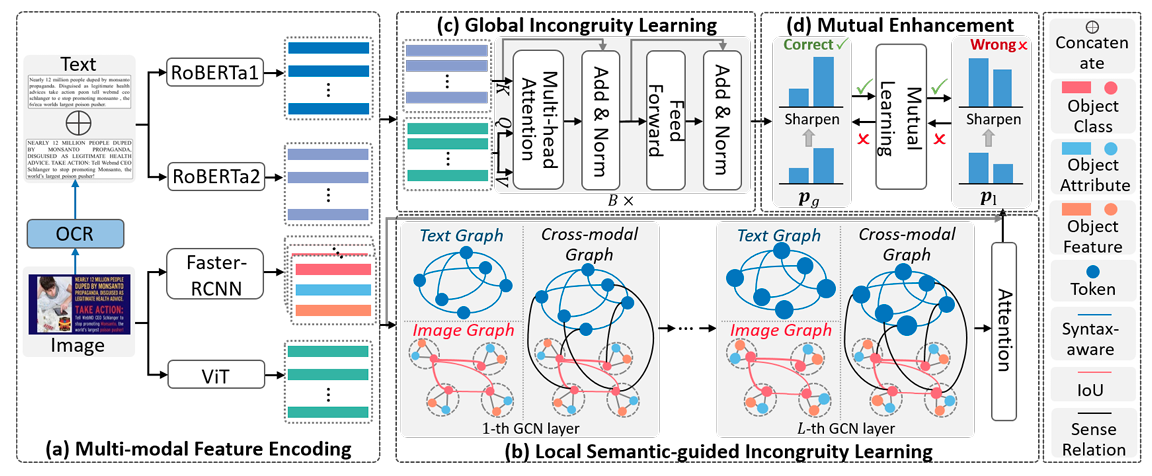
Mutual-enhanced incongruity learning network for multi-modal sarcasm detection
Yang Qiao, Liqiang Jing, Xuemeng Song, Xiaolin Chen, Lei Zhu, Liqiang Nie
Proceedings of the AAAI Conference on Artificial Intelligence 2023
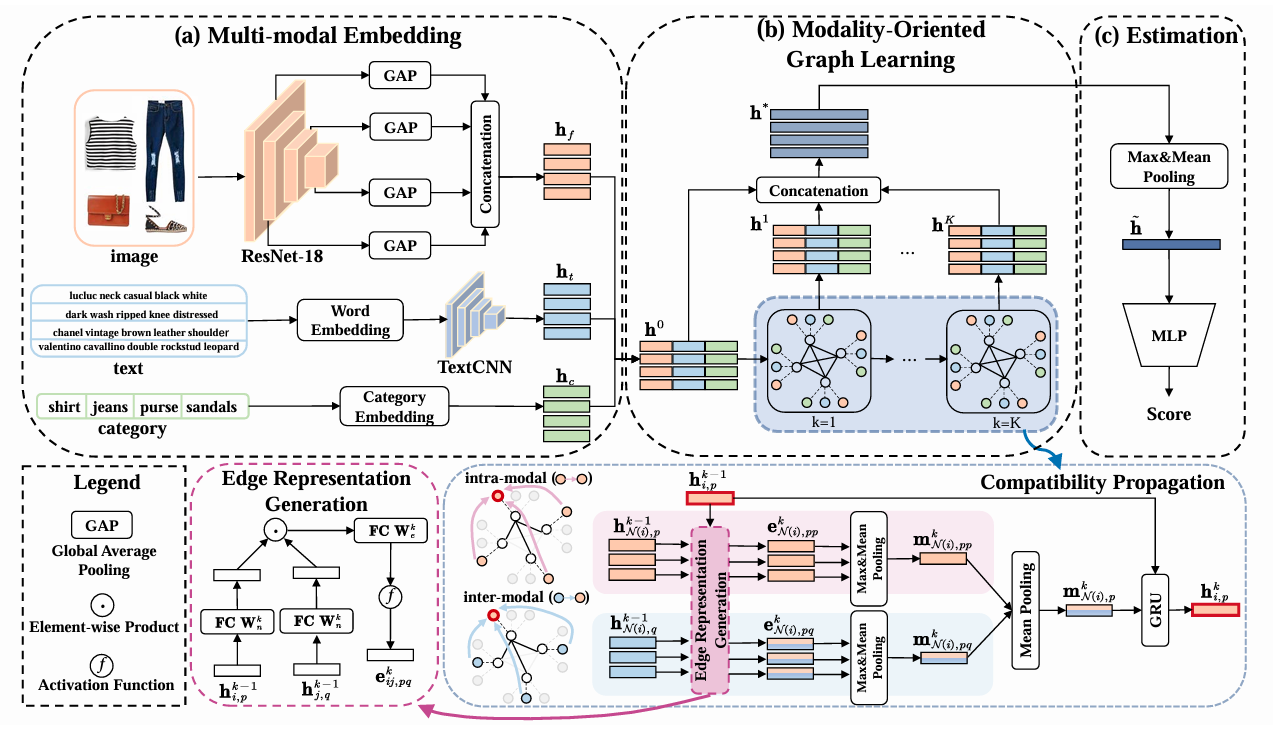
Modality-Oriented Graph Learning Toward Outfit Compatibility Modeling
Xuemeng Song, Shi-Ting Fang, Xiaolin Chen, Yinwei Wei, Zhongzhou Zhao, Liqiang Nie
IEEE Transactions on Multimedia 2023
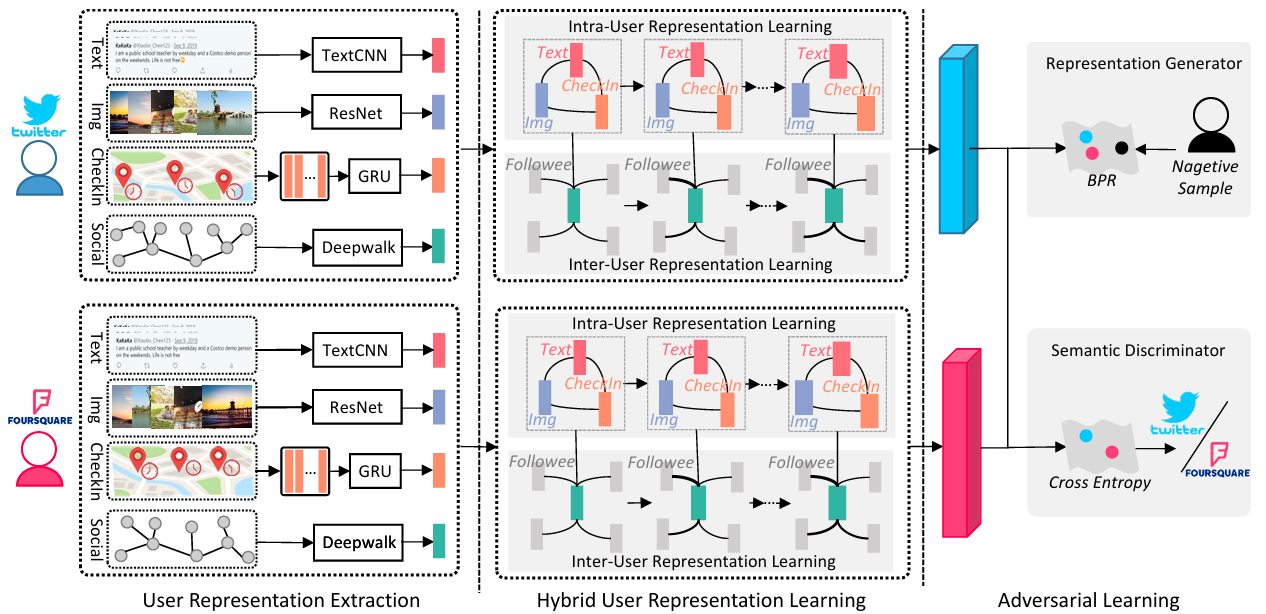
Adversarial-Enhanced Hybrid Graph Network for User Identity Linkage
Xiaolin Chen, Xuemeng Song, Guozhen Peng, Shanshan Feng, Liqiang Nie
Proceedings of the International ACM SIGIR Conference on Research and Development in Information Retrieval 2021
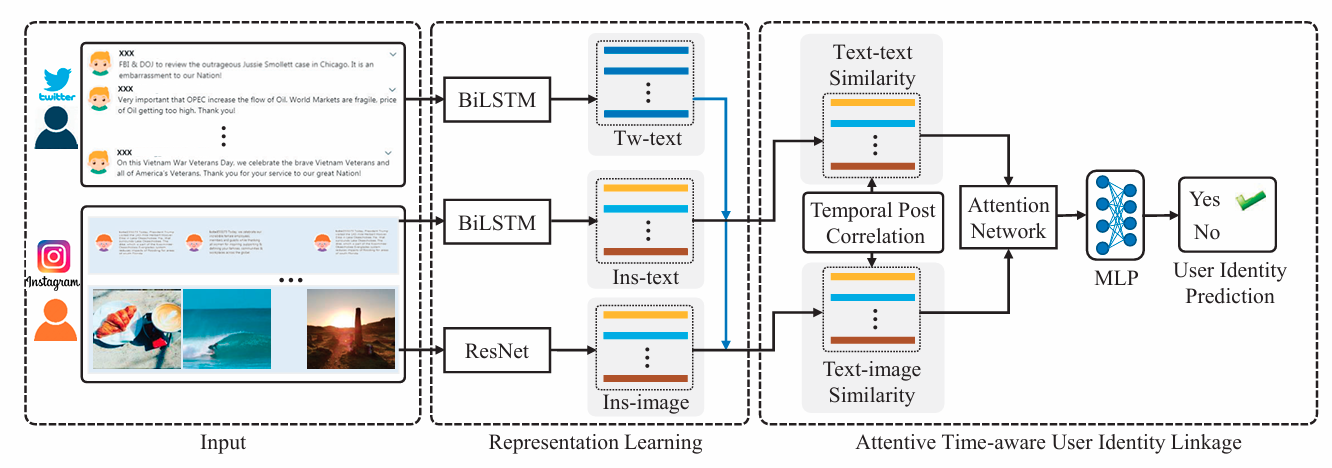
User Identity Linkage Across Social Media via Attentive Time-Aware User Modeling
Xiaolin Chen, Xuemeng Song, Siwei Cui, Tian Gan, Zhiyong Cheng, Liqiang Nie
IEEE Transactions on Multimedia 2021
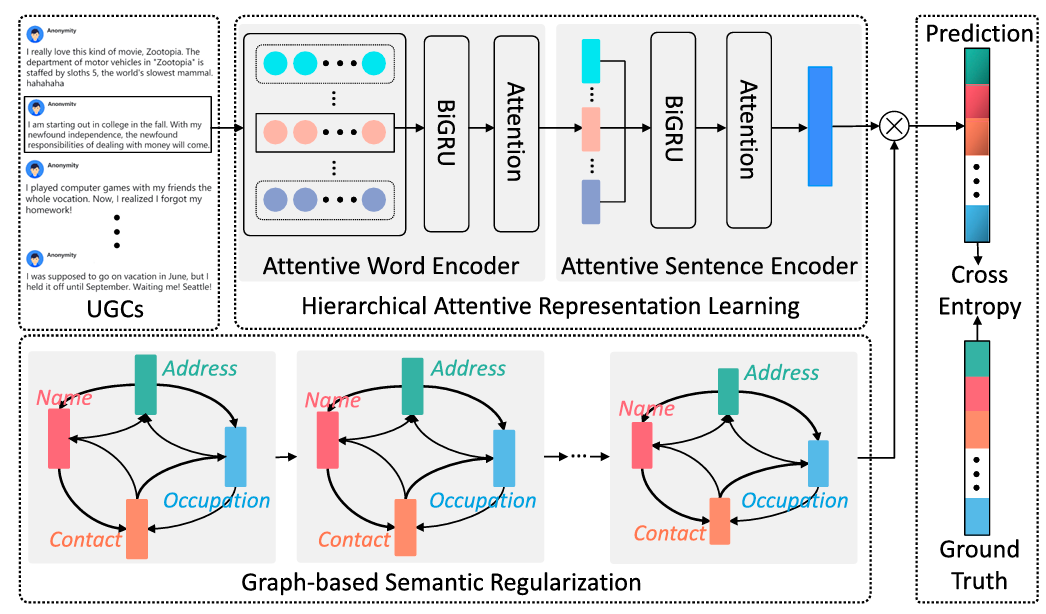
Fine-Grained Privacy Detection with Graph-Regularized Hierarchical Attentive Representation Learning
Xiaolin Chen, Xuemeng Song, Ruiyang Ren, Lei Zhu, Zhiyong Cheng, Liqiang Nie
ACM Transactions on Information Systems 2020